第一种解决方案:
第一步:去lr 的vugen的Tools -> Recoding Options -> Advanced -> Support charset -> UTF-8 选上。
第二步:设置IE,查看-编码-钩上“自动选择”和Unicode(UTF-8)(我的默认就是,又选了一遍才好的,不然好不了)。
第三步:设置Run-time Settings-Browser-Browser Emulation-Change。具体设置见下图。
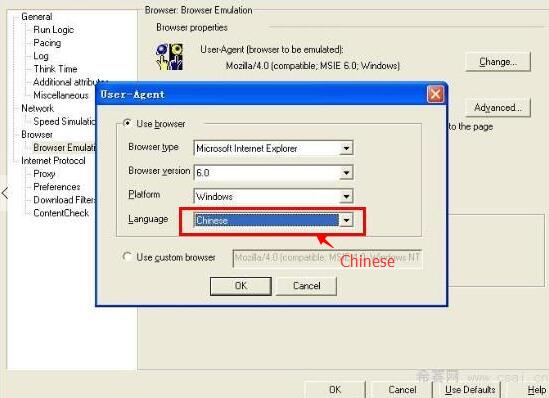
第四步:在lr的测试结果页面里面,什么也不选中,点右键,选择简体中文(因为我的LR的测试页面此时中文变成了乱码)。
第二种解决方案:
在LoadRunner中,为我们提供了一个字符串编码转换的函数lr_convert_string_encoding,用法如下:
int lr_convert_string_encoding ( const char *sourceString, const char *fromEncoding, const char *toEncoding, const char *paramName);
该函数有4个参数,含义如下:
sourceString:被转换的源字符串。
fromEncoding:转换前的字符编码。
toEncoding:要转换成为的字符编码。
paramName:转换后的目标字符串
我们需要把字符编码转换为UTF-8格式,因此用法如下:
lr_convert_string_encoding("汽车",LR_ENC_SYSTEM_LOCALE,LR_ENC_UTF8,"str");
这样一来,就成功地完成了字符串的编码转换。此时我们就可以对"汽车"这个参数进行参数化。于是最终的脚本编码看起来像这样:
lr_convert_string_encoding("lr_eval_string("{name}"),LR_ENC_SYSTEM_LOCALE,LR_ENC_UTF8,"str");
示例:
web_custom_request("CALL-H001I","EncType=text/xml;
charset=UTF-8", "BodyBinary=<request><meta><verb>CALL</verb><tid>H001I</tid></meta><data><assuid/><assutype>1</assutype><mortkind>04</mortkind><goodsasassuflag>0</goodsasassuflag><assuname>浣忔埧</assuname><papertype>01</papertype>
<paperno>鏆傛棤鍙风爜</paperno><paperrecedate/><papergrantorgan/><turncashabil>1</turncashabil>
<incrensuabil>1</incrensuabil><assuamt>1000000</assuamt>
<otherassuamt>1000000.00</otherassuamt><assuleftamt/><custid>A110102641122043#1</custid><custname>闇嶈景榫"
"""x99"
"</custname><repaynum>1</repaynum><firstmortrate/><secondmortrate/><mortstate>0</mortstate><note/><housetype>0</housetype><houseframesign/><houseformsign>01</houseformsign><housestylesign/><houseaddr>鍘﹂棬</houseaddr><housearea>100</housearea><compdate/><houseagreno/>
<carmarksign>A1</carmarksign>
<carmodel/><carno/><carengino/><carcolor/><caroutyear/><carrejeyear/>
<bankid>442000050</bankid>
<operid>031</operid></data></request>"r"n" "",
LAST);
使用函数:
char string[5000];
char tmp[10];
lr_convert_string_encoding(lr_eval_string("{name}"),LR_ENC_SYSTEM_LOCALE,LR_ENC_UTF8,"str");
//把字符串copy到tmp中。
strcpy(tmp,lr_eval_string("{str}")); sprintf(string,"BodyBinary=<request><meta><verb>CALL</verb><tid>H001I</tid></meta>
<data><assuid/><assutype>1</assutype><mortkind>04</mortkind><goodsasassuflag>0</goodsasassuflag>
<assuname>%s</assuname><papertype>01</papertype><paperno>鏆傛棤鍙风爜</paperno><paperrecedate/><papergrantorgan/><turncashabil>1</turncashabil><incrensuabil>1</incrensuabil><assuamt>1000000</assuamt><otherassuamt>1000000.00</otherassuamt><assuleftamt/><custid>A110102641122043#1</custid><custname>闇嶈景榫""x99</custname><repaynum>1</repaynum><firstmortrate/><secondmortrate/><mortstate>0</mortstate><note/><housetype>0</housetype><houseframesign/><houseformsign>01</houseformsign><housestylesign/><houseaddr>鍘﹂棬</houseaddr><housearea>100</housearea><compdate/><houseagreno/>
<carmarksign>A1</carmarksign><carmodel/>
<carno/><carengino/><carcolor/><caroutyear/><carrejeyear/><bankid>442000050</bankid>
<operid>031</operid>
</data></request>"r"n",tmp);
web_custom_request("CALL-H001I",
"EncType=text/xml; charset=UTF-8",
string,
LAST);
说明:
1. 在树视图里的源码(server Response)的乱码是没法解决的;
2. 在树视图的页面显示可以是正常,源码视图也可以显示正常;
3. 虽然在server Response显示乱码,但查找中文字符串还是正常的。