
本来想写一篇类似《一文说透精准测试》之类的爽文的,奈何能力有限,还是先写一篇短文吧。
本文就只涉及一个点,精准测试能用来干嘛,解决了什么问题。笔者通过整理腾讯、酷家乐 、网易、有赞、信也等互联网行业的精准测试实践分享,以及与星云等解决方案厂家的介绍,尝试给精准测试的成熟度模型做一个提炼。
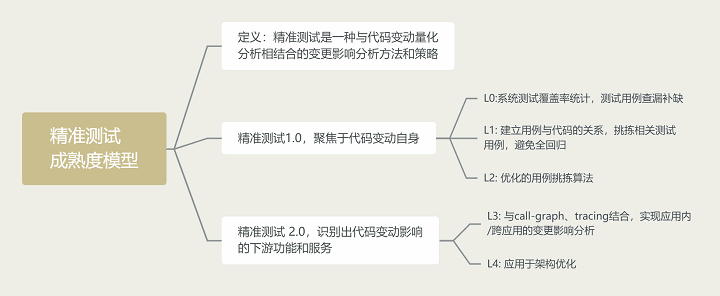
首先,从定义上讲,精准测试是一种与代码变动量化分析相结合的变更影响分析方法和策略。
基于风险的测试是一种行之有效的测试策略。“步步高点读机,哪里不会点哪里”,很好地说明了这种方式的有效性。对于软件测试来说,每次发布变动的地方,如代码、配置项、依赖等等,就是最有可能产生缺陷的地方。对于这些地方,尤其是代码的优先和充分的覆盖,就是一件非常自然而然的事情了。
而精准测试1.0 就是这种思想与代码覆盖率统计相结合的产物。
精准测试1.0, 聚焦于代码变动自身
在这个阶段,主要关注于如何覆盖被测应用变动代码的部分。笔者尝试着用将其分为以下的阶段:
L0:系统测试覆盖率统计,测试用例查漏补缺
这个时候团队不再满足于黑盒测试,开始关注代码,关于测试活动对于代码,尤其是变动部分代码的覆盖情况。将代码覆盖率统计报告应用于测试活动中,根据覆盖率报告来验证测试效果,并调整补充测试。并可能衍生出诸如系统测试增量代码覆盖率等发布质量指标。
L1:建立用例与代码的关系,挑拣相关测试用例,避免全回归
这是通常意义上的精准测试的由来,也是最先被互联网大厂提出的测试实践,也是为精准测试带来大量争议的实践。这种方式以覆盖率统计技术为基础,实现单个测试用例的覆盖率统计之后,通过倒排建立代码中类和方法与各个测试用例之间的关联关系。由此,当某个类或者方法发生改变时,可以有限或者仅仅执行该部分用例。这种方式一方面是可以节约大量的回归工作量,也可以让可能的缺陷更快速地被发现并报告。由此,谓之精准测试。
L2:优化的用例挑拣算法
实践当中,覆盖了某个类或者方法的测试用例数量还是相当多的,存在大量的冗余与噪音。例如,如果不同的用例中可能都存在登录步骤,而如果登录方法发生改变的话,岂不是约等同于全回归,而期望的可能只是将登录部分用例进行回归。因此,在初步建立了双向可追溯的关系之后,还需要通过优化算法,来实现测试用例的裁剪。例如,在用例执行过程中,如果某个用例在执行后,虽然这个用例也覆盖了该方法,但是由于某个方法的测试覆盖率没有增加,因此该用例可以判定为冗余用例被裁剪掉。通过几轮次后,可以以最少的测试用例集来达成最大的覆盖率。这个过程,类似于从面粉中提取面筋的过程。。。
当然,这个阶段的所谓精准测试重度依赖于自动化测试以及代码覆盖率。因此,笔者一直认为,这个阶段的精准测试是一种治疗富贵病的药。对于广大连自动化用例都没有,或者只能涵盖冒烟测试的团队来说,先追求小康能吃饱吃好才是硬道理。
精准测试 2.0, 识别出代码变动影响的下游功能和服务
进入到精准测试2.0,标志着对于变更影响范围的识别从变动的代码自身,扩展到了这些代码的变更所影响的应用自身的其它代码,甚至是整个微服务的调用链图谱。
L3:与call-graph、tracing结合,实现应用内/跨应用的变更影响分析
在微服务应用内部,某个service方法a可能被其它的service如b,d,d所调用。如果a发生了变化,可能b,c,d由此产生意外的缺陷。类似的,某个微服务的接口A发生了变化,在上游调用了接口A的微服务接口B,C,D们也可能会受到影响。这些影响在设计、开发、测试过程中都需要进行分析和覆盖,以确保不会产生缺陷。于是,这就进入了精准测试L3的阶段。
目前来说,结合应用内部的动态、静态调用链分析,以及tracing 等技术,可以实现应用内部以及服务间的call-graph,从而建立起这样的精准变更影响分析能力。
当然,除了接口间的依赖之外,方法之间应用之间还有一些之间或者间接的依赖,如数据库表和字段以及消息中间件中数据生产和消费者之间的依赖。还需要通过数据库的血缘分析以及消息中间件topic订阅的数据来补充完善。
L4:应用于架构优化
到了这个阶段,主要是上述数据的应用扩展。除了提供应用变更时的影响分析之外,还可以揭示例如接口循环依赖、重复调用设计层面的问题,提高整个微服务架构的合理性。
那么,精准测试的3.0或者L5级别会是什么呢?